The Problem – Trust in the Information Age
The Internet and social media have scaled the size of the groups we can communicate with, but our ability to track the reputations of individuals within those groups hasn't scaled well at all. We can connect with more people, but it's more difficult to determine who deserves to be trusted.
Hive.one aims to solve this problem with an algorithmic approach.
Solution – The Hive.one Algorithm
Rather than embracing the idea that we need centralized "arbiters of truth," Hive.one is building a decentralized and transparent "reputation layer for the internet."
Their core innovation is an algorithm that quantifies reputation. This will make it easier to keep track of other people's reputations at scale and will also make reputation transferable, allowing users to bring their reputation with them across different communities and systems.
Their algorithm calculates influence ("attention") scores by examining the Twitter follow graph.
- If a member of a specific cluster (a community) follows you, it adds to your score.
- The more influential the new follower is and the fewer other accounts it follows, the more your score is boosted.
- Attention scores are an approximation of one's status within a group. A higher score represents a greater ability to exert influence over the group.
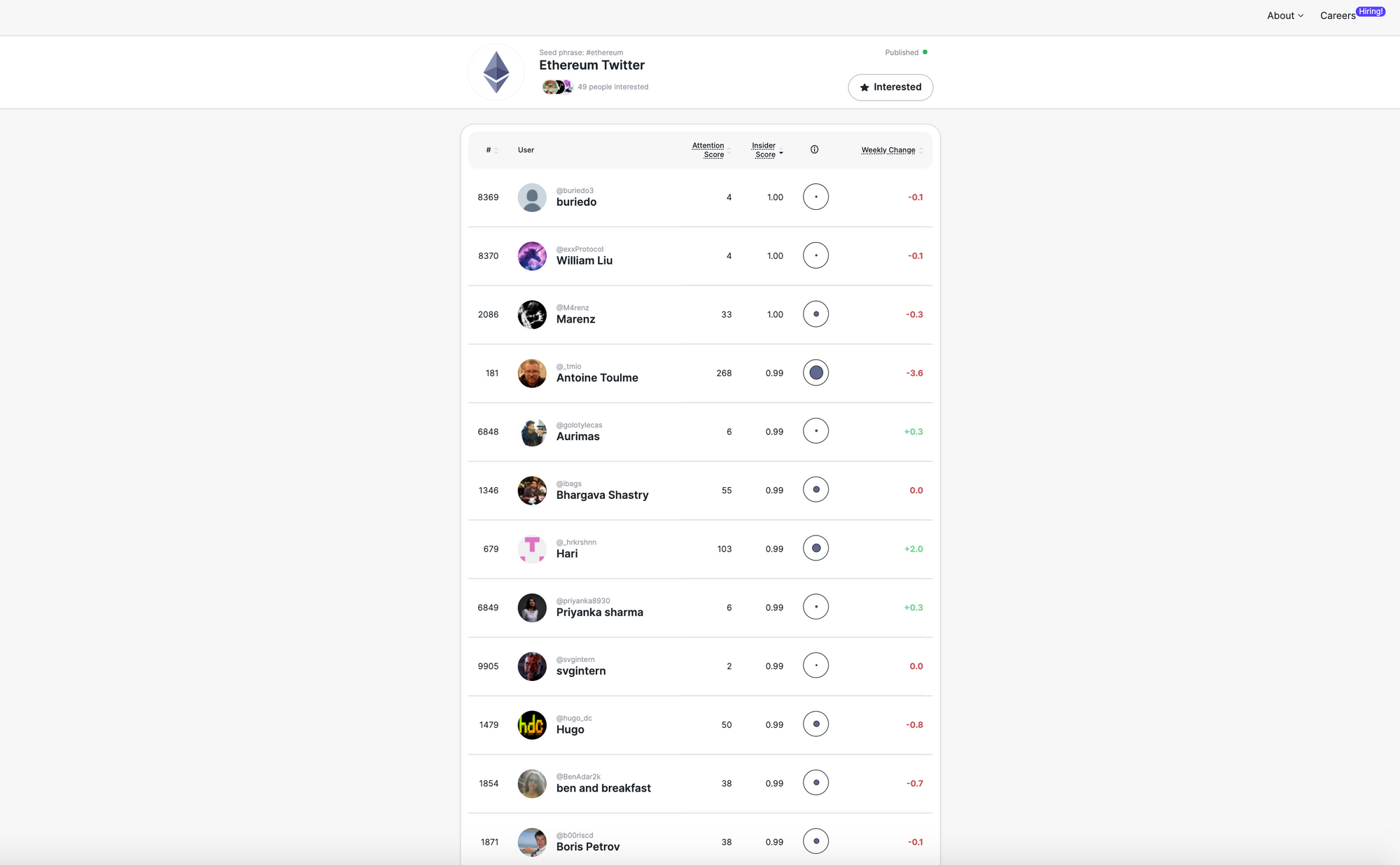
As one might expect, Ethereum co-founder Vitalik Buterin has the highest attention score within the Ethereum community.
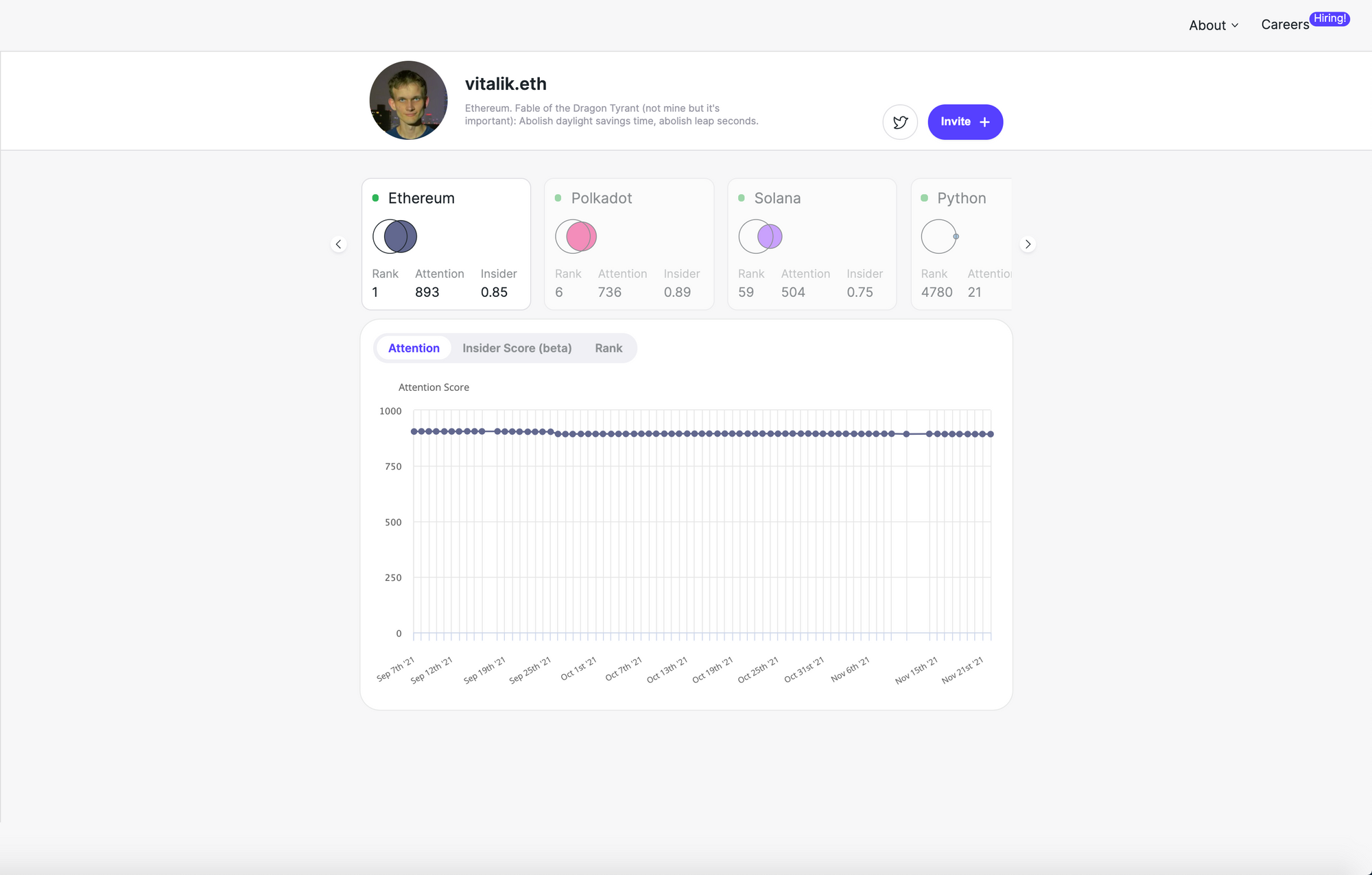
The insider score is a compliment to the attention score. Insider scores tell you whether or not somebody "belongs" in a given community. Your insider score is high if people who pay a lot of attention to other accounts with high scores pay attention to you as well. Vitalik's insider score is lower than his attention score because he's followed by many people from outside of the Ethereum community.
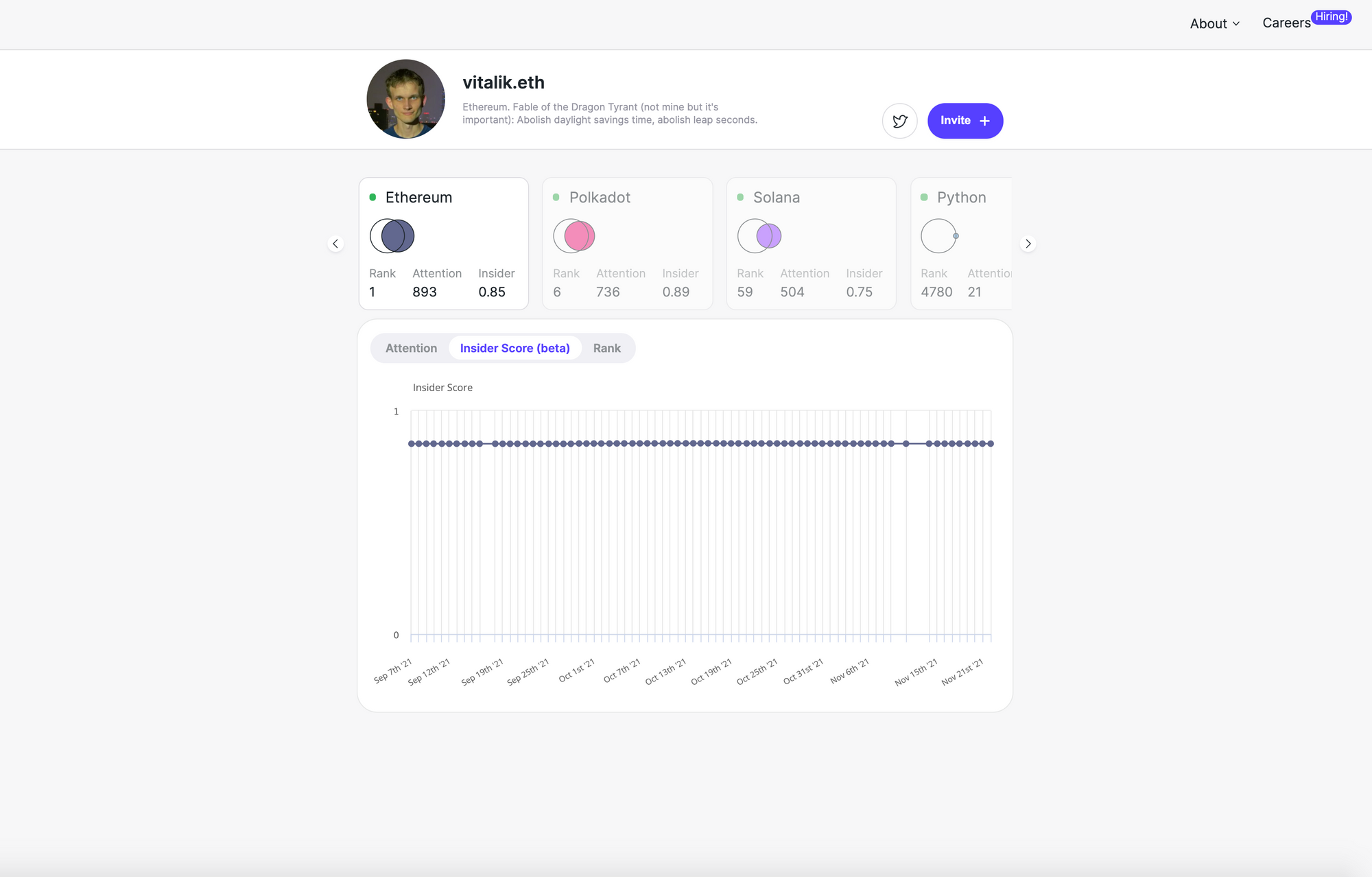
Measuring influence based purely on follows is a limited approach, so the team is working on incorporating other signals that track attention such as retweets and replies. Hive.one co-founder Maciek Laskus has done some deep thinking about how to quantify influence in his blog posts What is Influence and Attention as a Source of Scarcity for Decentralized Identity Systems.
The algorithm is currently closed-source, but the team may eventually open-source parts of it and plans to decentralize control over it over time.
The more Hive.one gets used, the better the model gets. The better the model gets, the more people use it. The social graph will be indexed like Google indexed the web. However this graph will be open, permissionless, and free for anyone to build on top of or fork.
All the platform's data can be accessed through their API.
Communities
Communities ("hives") are groups of people with a shared interest.

Hive.one has built an automated model that "can find communities of people and do it accurately enough to satisfy insiders." While the first version of the algorithm relied on a seed list of accounts to find communities, the most recent update allows it to find them based on a single word input.
Hive.one users can customize their experience by saving communities to their group of "interests." Selected interests are made public which enables other users to curate based on the interests of others, and allows developers to build on the open graph.
Hive.one serves as a bridge between Reddit's model where you follow communities that form around shared interests, and Twitter's model where you follow a diverse set of individuals with varying interests.
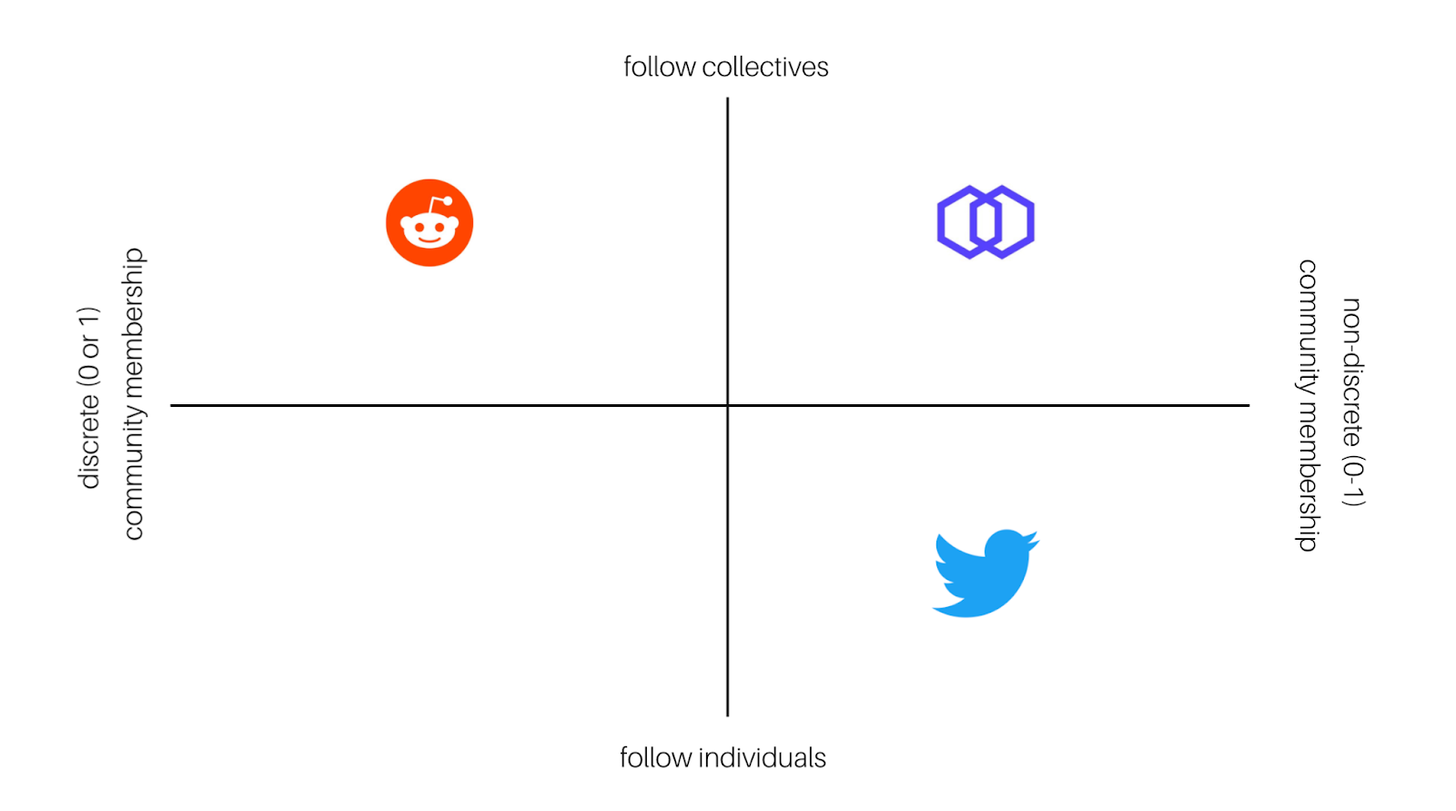
This sort of automated curation of communities could have several valuable practical applications as it scales and is refined.
Enthusiasts and experts within communities will have an easy way to assess who is most influential within their niche. This could serve as a valuable research tool and guide important personal and business decisions.
Newcomers who want to understand a new field or community would have a convenient way to dive in and get a sense for who they should follow in order to learn as quickly as possible.
The team has stated they'll be indexing other platforms besides Twitter. New platforms will be added based on which ones are the most popular among the communities that use Hive.one most often.
Example: Evaluating Hive.one's Ethereum Community
Let's examine the Ethereum community to see how Hive.one's algorithm performs at measuring influence and identifying community insiders.
Most of the accounts with high attention scores I recognize as being influential within the Ethereum community, although I'd make some major tweaks to the rankings. The algorithm does a fairly good job at identifying influential community members.
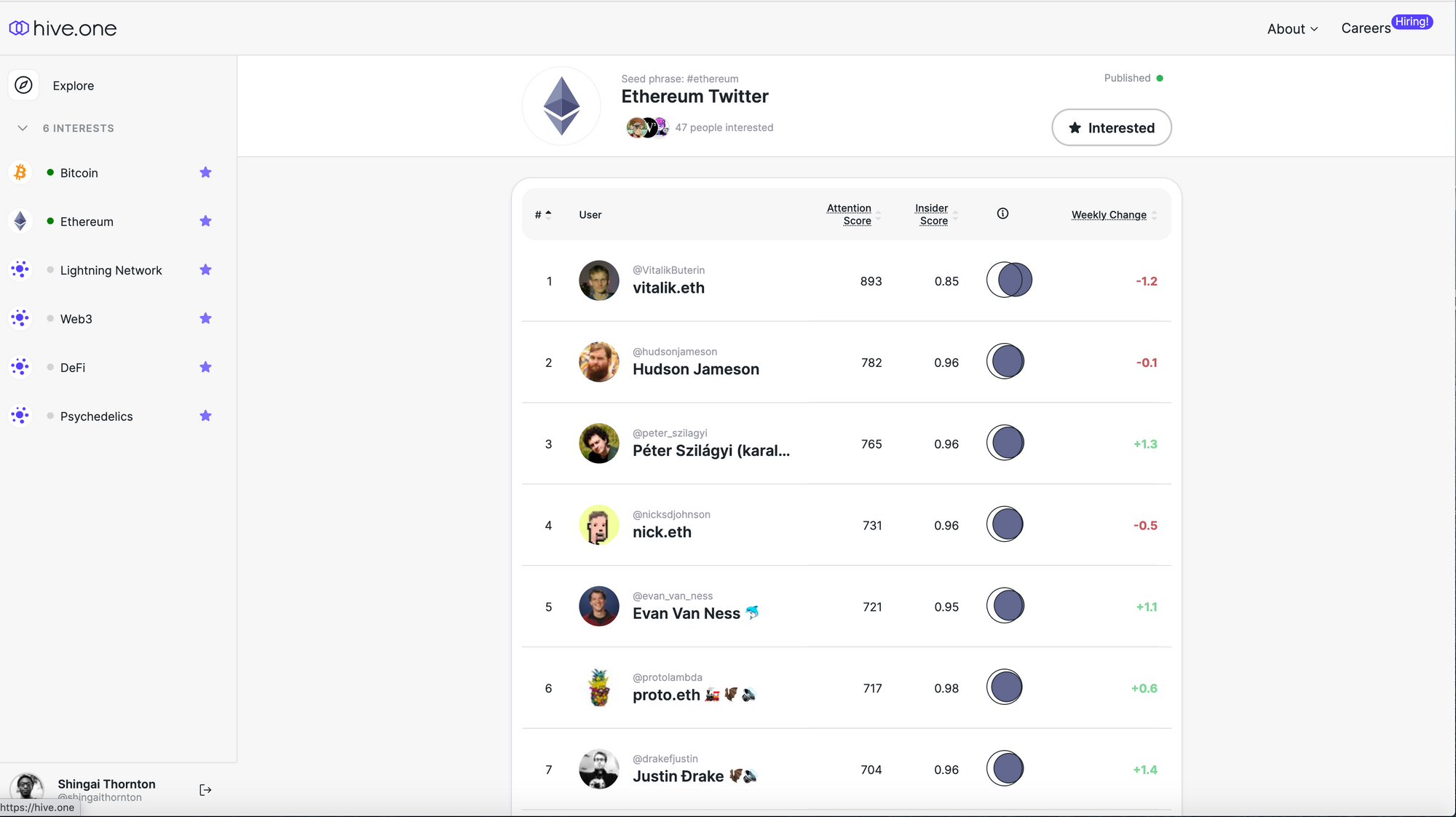
However, many of the accounts with the highest insider scores (ie: the entire first page) don't seem to clearly "belong" in the Ethereum community. There are several unknown or anonymous accounts with no observable relationship to Ethereum. All of the prominent accounts with high attention scores (Vitalik Buterin, Joseph Lubin, Hayden Adams...) "should" have higher insider scores. In its current form, the insider score isn't very useful. The feature is still in beta and the team is working on a new version designed to improve its accuracy.
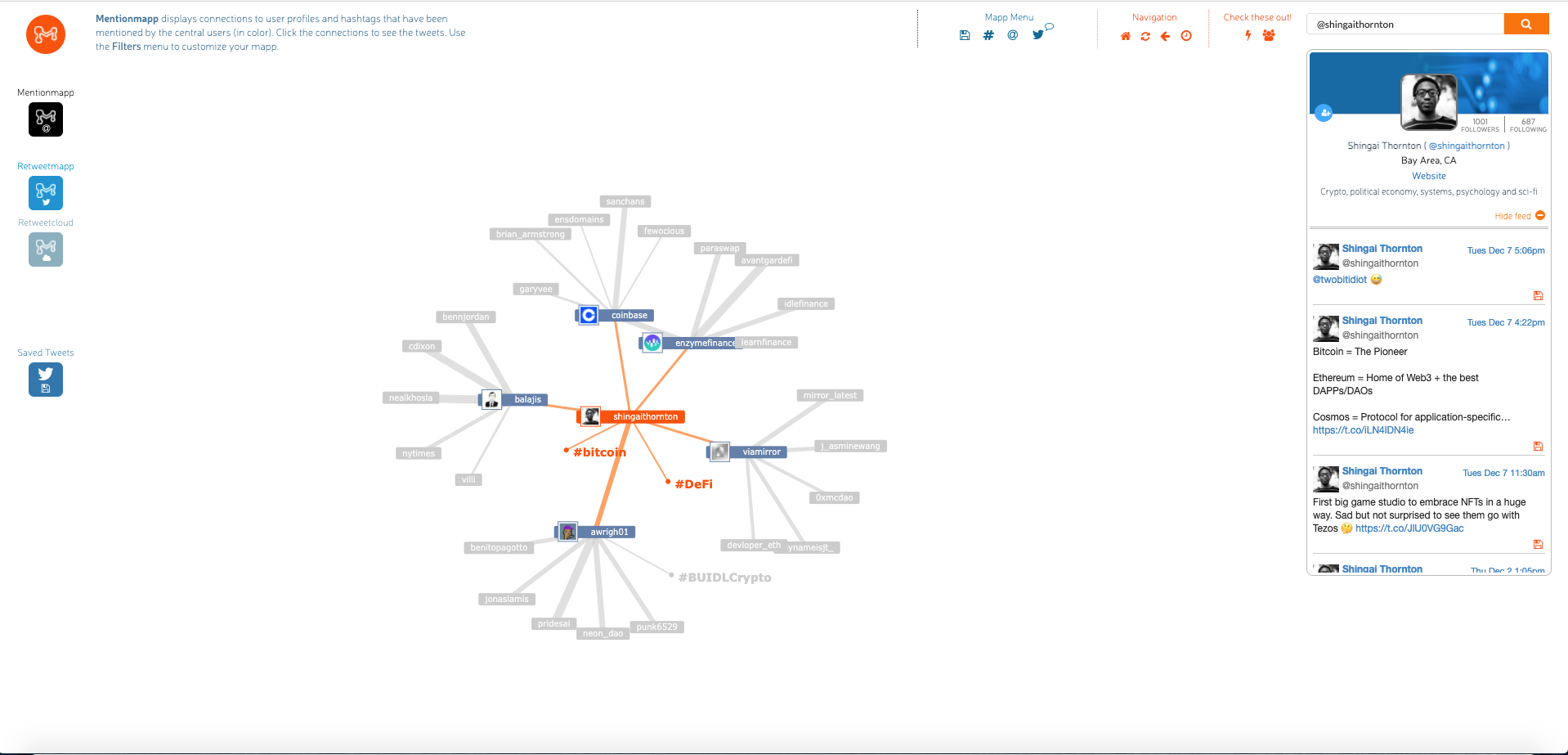
Rather than presenting the scores on a 0-1 scale. I'd love to see something more interactive and aesthetically appealing like a network visualization. Communities could be represented as collections of interconnected nodes, with node size/color being used to indicate influence – Mentionmapp is one product that displays Twitter content using network visualizations. According to Maciek, the team is actively "working on new ways of exploring the graph and relationships between communities, including visual interfaces."
Final thoughts
The Hive.one team envisions a future where users can move with their reputation between social media platforms, Web3, and other apps. The final phase of their roadmap will see the launch of thousands of budding hives.
This is a noble vision for what could evolve into an incredibly valuable digital public good.
As the project grows there are a few things I'll be keeping a close eye on:
- How will the team determine how much of their algorithm to open-source? Which parts will remain closed, and why?
- How will decentralized control over the algorithm be achieved? (The team is still working on this and isn't quite ready to share details)
- I'm really excited about the possibilities for navigating the most popular content within communities. Content ranking is on their roadmap, what will their approach be?
